| 送交者: 雪狼99[☆★★★声望勋衔15★★★☆] 于 2024-02-23 12:15 已读 11341 次 | 雪狼99的个人频道 |
图源:OpenAI官网(Sora生成视频截图)
“卷”了一年的“百模大战”还未结束,海外AI巨头OpenAI又给国内科技战队出了难题。
春节期间,就在大家都在把酒言欢时,OpenAI毫无征兆地放出了AI新“核武”——文生视频模型Sora。
令人直呼不可思议的是,Sora能够根据用户的文本描述生成长达60秒1080P高质量的视频,其中包含精细复杂的场景、生动的角色表情以及复杂的镜头运动。英伟达人工智能研究院首席研究科学家Jim Fan高呼,“Sora是一个数据驱动的物理引擎,这是视频生成领域的GPT-3时刻。”
6park.com 在视频流畅性、清晰度、文字理解、及对真实物理世界的还原等方面,Sora的表现已远超主流AI视频工具前辈Pika、Runway、Gen-2等,可以说是“一骑绝尘”。
去年,在ChatGPT问世后,国内百度、阿里、腾讯等互联网大厂,以及清华、浙江大学等学院派机构纷纷涌入大模型赛道,争抢人工智能变革时代的入场券。众多初创企业也撸胳膊挽袖子地齐上阵,试图寻找弯道超车的机会。
而如今,文生视频模型Sora的诞生,不出意外也会再次掀起一波激战的浪潮。
从当前节点来看,国内在文生视频“角斗场”中有哪些选手入场?正在研发的文生视频项目做到了什么阶段?存在的发展瓶颈有哪些,和海外的差距究竟在于什么?
Sora横空出世,国内差距明显
短短一周内,国泰君安、天风证券、华泰证券等20余家证券机构均在研报中表示,OpenAI发布的Sora模型是AI发展的又一里程碑,文生视频迈入新时代,有望引领多模态大模型浪潮。
天风证券认为,随着OpenAI发布Sora文生视频模型能力大幅提升,内容创作工作流有望被颠覆,下一个亿级用户的互联网平台雏形已然出现。2000亿美元的短视频创作生态有望率先被颠覆,生成式AI在视频创作和世界模型的大踏步进步将实现对视频、3D、游戏等下游应用场景的渗透。
据了解,国内科技公司在文生视频领域已有布局。据公开资料显示,包括字节跳动、腾讯、阿里、百度、虹软科技、爱诗科技在内的一众科技公司都在积极布局文生视频模型。但遗憾的是,目前国内大多数文生视频模型仍处在技术研发阶段,暂未有能与Sora能力相匹配的完善产品落地。
在Sora引爆文生视频赛道前,字节跳动就曾提到计划推出一款创新性视频模型——Boximator。但与Sora、Pika不同的是,Boximator目的是通过文本精准控制生成视频中人物或物体的动作。字节跳动相关人士也对搜狐科技做出了回应,“Boximator是视频生成领域控制对象运动的技术方法研究项目,目前还无法作为完善的产品落地,距离国外领先的视频生成模型在画面质量、保真率、视频市长方面还有很大的差距。”
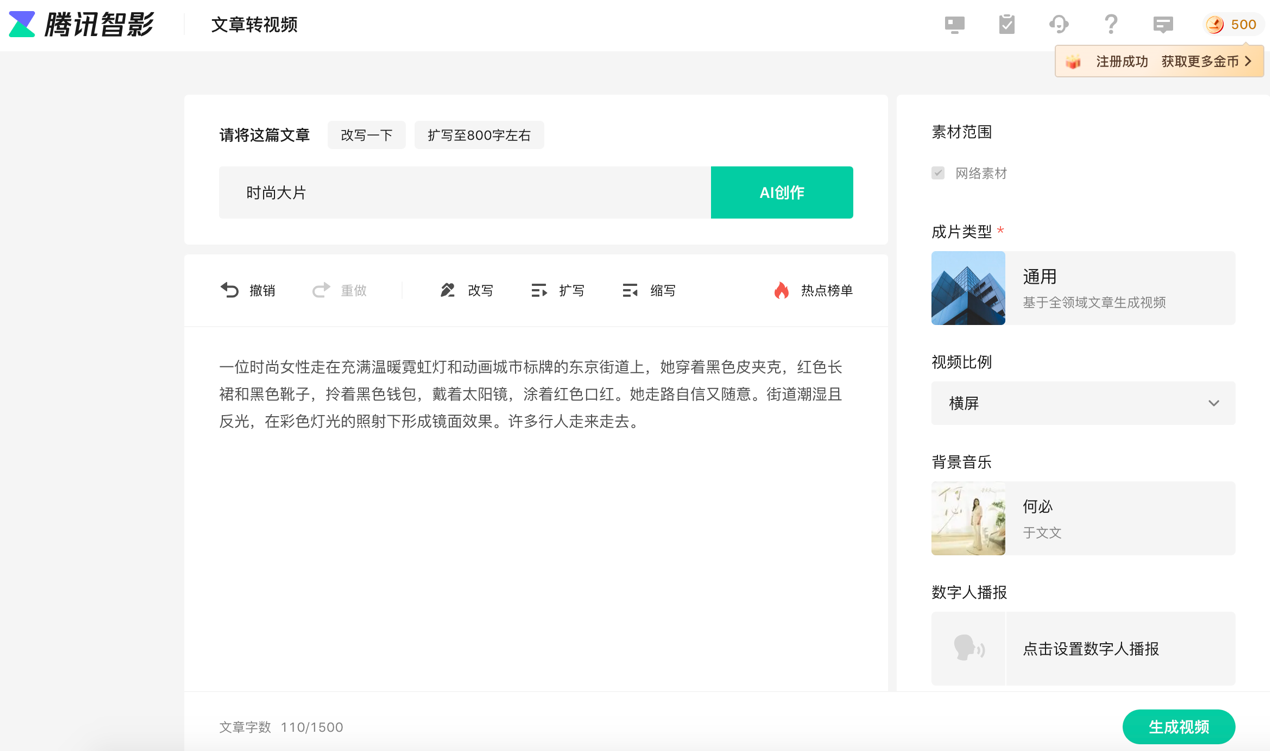
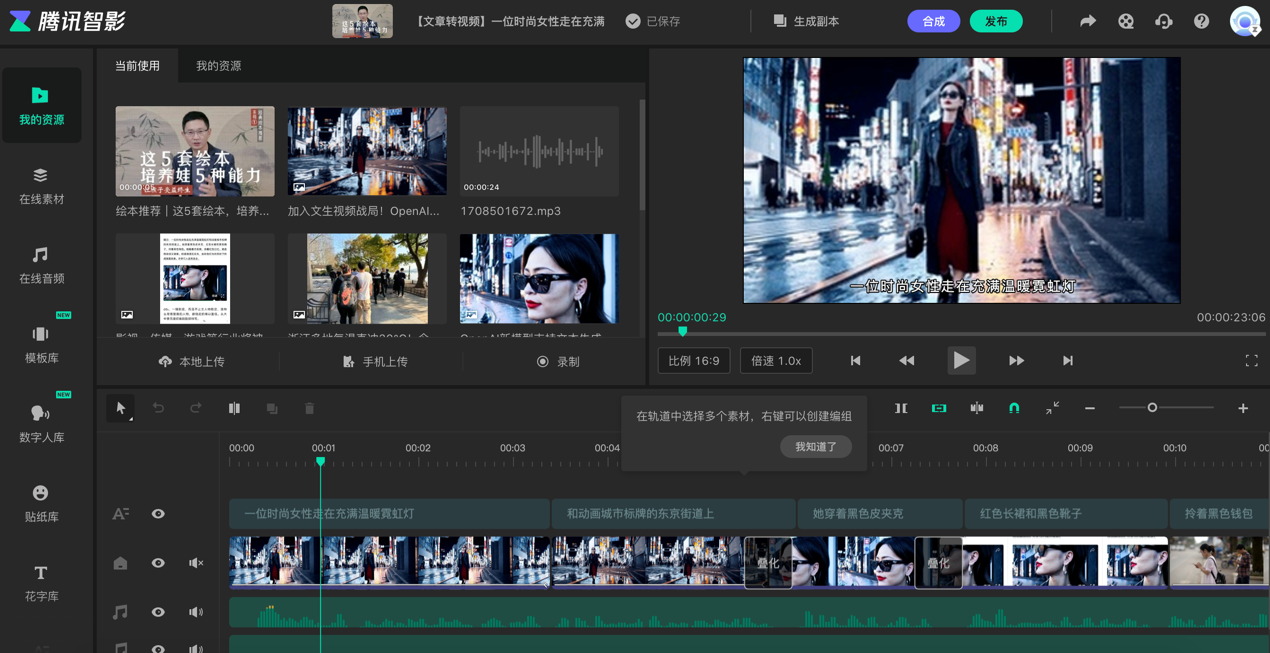
搜狐科技挑选了一款可供测试的腾讯文生视频产品“腾讯智影”进行实测发现,其应用场景主要聚焦于生成数字人播报视频。当输入与给定Sora命令相同的文本后,经过几分钟的等待时间,其利用网络现有视频素材进行拼接生成视频,并配以文字和语音播报。但显然,这与大家期待的Sora级别生成视频不是一个概念。
图源:腾讯智影测试截图 图源:腾讯智影测试截图 如今Sora模型推出,国内暂未有与之跟进的大模型出来。一些人也因此认为,和OpenAI相比,我们的大模型能力差距没有缩小,反而在扩大。
浙大教授:国内勇于试险的人太少
据悉,Sora是一个扩散模型(Diffusion Model),是在大量不同时长、分辨率和宽高比的视频及图像上训练而成的。
浙江大学人工智能研究所所长吴飞对搜狐科技介绍,Sora在视频呈现效果上有优异表现的背后原理为“对合成内容中最小单元进行有意义关联组合”。Sora通过观察和学习海量数据视频后,洞察了视频中时空子块单元(space-time patch)在运动、颜色、光照和相互遮挡等维度上所应该保持的物理规律。虽然Sora并不能像人类理解牛顿定律一样理解这些物理规律,但在合成视频时,Sora可以记住时空子块单元之间应该遵守的模式,并在合成过程中用这些模式来约束时空子块组合,从而呈现出逼真的视觉效果。 6park.com
6park.com很多人疑惑,中国也在很早就意识到大模型多模态(处理图片、语音、视频等信息)发展的重要性,为什么这一次还是落后了?
浙江大学计算机科学与技术学院教授汤斯亮对搜狐科技表示,自己所在的团队近两年也在进行文生视频项目的研发工作,从国内的研发进展来看,目前无论是在视频的时长、分辨率、清晰度、场景转换的流畅性还是对物理世界的规律的还原性上,都与Sora还有不小差距。国内的主要问题在于之前对于文生视频技术发展的前景预判不足,过于保守,导致在资源(算力、资金等)上的投入不够。
汤斯亮在对话过程中指出限制国内技术发展的主要影响因素为大算力、大数据、以及先进算法,三者需要相互匹配。
在汤斯亮看来,国内发展AI技术最大的限制首先是与视频大数据匹配的大算力。OpenAI究竟用了多大量级的视频数据去做Sora训练目前没有披露,但从视频清晰度和其生成的视频多样性(电影、短视频、监控视频、广告、游戏等)来看,肯定是用了大量的高清视频样本,训练尺度(training scale)肯定是惊人的,可能是之前文生视频模型训练量级的千倍甚至更多。
他介绍,就算力消耗而言,视频预训练和文本预训练也完全不是一个数量级。因为在学习视频编码到隐空间向量的过程中,需要从每个视频帧中提取大量特征,由于视频存在大量的时间与空间的冗余性,使得其编码效率远低于文本,训练与文本预训练相同参数量的模型需要用到更多的数据,消耗的算力可能会在几个量级以上。另外,在利用扩散模型将隐空间向量解码回视频的过程中,要想生成的视频达到如此高的分辨率,对于算力的需求也是成倍增长。如何能够保证在如此大规模的训练数据下,利用海量的分布式算力,持续稳定的训练Sora大模型,体现了OpenAI在大算力大数据匹配方面的技术积累。 6park.com
6park.com“第二个差距在于数据方面。相较于高质量的文本和图片数据,高质量的视频数据样本数量本身较少,版权限制也比较多,图文匹配数据的标注、清洗难度也大很多。尤其是对于企业来说,以盈利为目的去收集数据会受到限制。”
汤斯亮把算法放在了最后来谈,是因为他认为研发并应用先进算法的风险较高,目前从公开披露的消息来看,大部分企业即使是OpenAI,也尽量避免采用全新的技术路线,而是在不断推动现有技术路线的边界。
他提到,扩散模型(diffusion model)的概念最早在2015年就有了,国内的团队也一直在探索和应用。对于Sora来说,它的成功得益于OpenAI敢冒风险,舍得花费大量的钱和时间去不断调优现有技术框架,探索与视频大数据、大算力匹配的可用技术,而非全新技术。
“收集、存储、标注、以及要将大量的视频数据样本在系统中跑起来,这个成本可以说是相当高的。但国内的现实情况是,在Sora出现前,几乎没人相信花这么高成本去做文生视频这件事能带来多大收益,因此没有人愿意试险。”
他表示,未来类似于transformer这样的全新算法可能会越来越少,因为一个全新算法想要替代现有的主流算法框架,其运行、测试验证等过程需要消耗的成本巨大,并且谁也没法保证新算法跑出来的效果就比之前的好,没人愿意担风险,因此现在大家更多都是在做对现有模型的小修小补。
谈及距离国内实现OpenAI类似级别的应用落地还需要多久时,汤斯亮毫不忌讳地说,“在国内环境做的话,肯定和OpenAI是不一样的,国内投资对于回报的压力比较大,肯定是以短期内能盈利为目的。如果能看得到明确的商业应用场景,并且有足够数据和算力的情况下,实现周期会很快,可能一年内就会有差不多的应用做出来。但如果相反,两到三年都有可能。”
他认为,“在这条赛道上,企业会比院校跑的更快些,因为企业有更多的算力和资金。这个时候想法不值钱,能做出来才有价值。” 6park.com
6park.com吴飞对此表示,“AI发展是一个技术、人才和资本三者结合的高新产业。国内的短板在于原始创新人才不足,在这一深度学习为主的人工智能崛起中从0到1的理论模型都不是从中国提出,中国的科学研究往往采取了跟进模式。OpenAI在Sora的成功,是技术创新、顶尖人才和资本投入的组合。”