| 送交者: 我在枫林中哭泣[♀☆★★★女中豪杰★★★☆♀] 于 2023-05-24 18:56 已读 14999 次 | 我在枫林中哭泣的个人频道 |
AI大模型+人形机器人,迈出了通向通用人工智能的一大步。 机器人进化路径:从固定到移动,从独立到协作,从单一到通用。服务机器人商业化落地的前提是产品能提供真实价值,真实价值的判断在于机器人能否通用。把机器人做成人形,就是为了使机器人的执行能力更加通用,上游核心零部件随着协作机械臂的兴起快速发展,促进了人形机器人硬件本体制造能力的提升,同时伴随自动驾驶技术的高速发展,人形机器人在视觉、SLAM与基础AI上有了更多的方案选择,大模型的出现,会从语音、视觉、决策、控制等多方面实现同人形机器人的结合,形成感知、决策、控制闭环。我们认为机器人产业将进入渗透率快速提升的新阶段,看好机器人产业发展前景。 AI大模型从语音、视觉、决策、控制等多方面实现同人形机器人的结合,形成感知、决策、控制闭环,使机器人具备常识。
1)语音:语言大模型为机器人的自主语音交互难题提供了解决方案,在上下文理解、多语种识别、多轮对话、情绪识别、模糊语义识别等通用语言任务上,ChatGPT显著优于深度学习,表现出了不亚于人类的理解力和语言生成能力。
2)视觉:人形机器人的场景相对工业机器人更通用、更复杂,通用视觉大模型的All in One 的多任务训练方案能使得机器人更好地适应人类生活场景:大模型的强拟合能力使人形机器人在进行目标识别、避障、三维重建、语义分割等任务时,具备更高的精确度;通用视觉大模型通过大量数据学到更多的通用知识,并迁移到下游任务中,基于海量数据获得的预训练模型具有较好的知识完备性,提升场景泛化效果。
3)决策:基于多模态的预训练大模型将增强机器人可完成任务的多样性与通用性,让其不局限于文本和图像等单个部分,而是多应用相容,拓展单一智能为融合智能,使机器人能结合其感知到的多模态数据实现自动化决策。
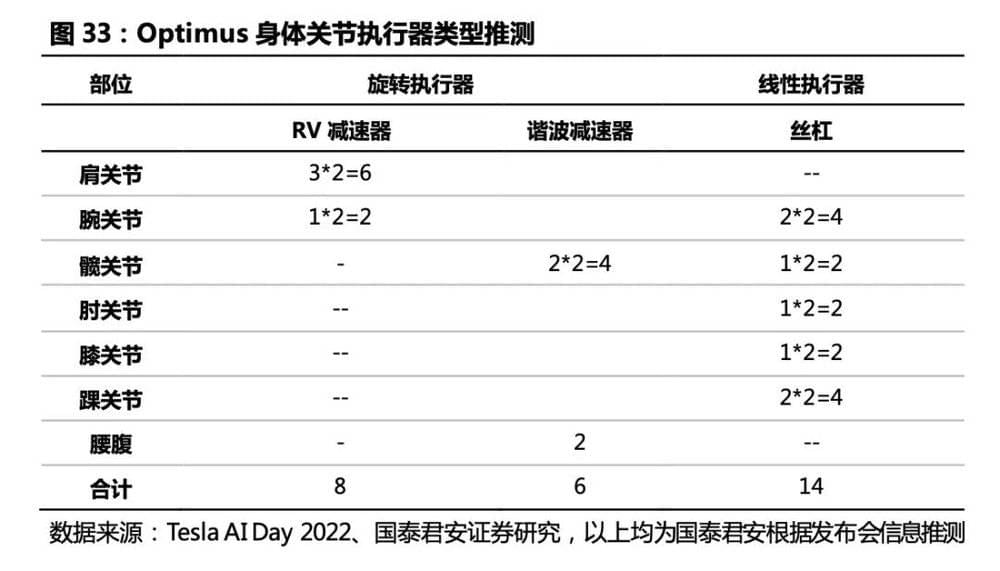
驱动:相比工业机器人,人形机器人硬件需求更复杂、更多元,特斯拉采用的电驱方案具备商业化应用基础。1)特斯拉Optimus采取电驱方案,预计全身共40个执行器,其中:身体关节28个执行器,旋转关节方案采用伺服电机+减速器方案,我们推测单台人形机器人将搭载6台RV减速器(髋、腰腹)和8台谐波减速器(肩、腕);我们猜测摆动角度不大的关节(膝、肘、踝、腕)采用力矩电机+行星滚柱丝杠方案,将使用14个线性执行器。
2)机械手采用微型电机+腱绳驱动传动结构,单手6个电机,11个自由度。空心杯电机结构紧凑、能量密度高、能耗低,和人形机器人机械手需求契合度高。
减速器、伺服电机、线性执行器、滚柱丝杠是人形机器人的运动控制产业链中价值量较大的硬件设备。1)电机:数量更多、品类更丰富,需满足全身各关节的驱动需求,手部需采用微型电机。
2)减速器、传动装置:数量更多,旋转执行器延续了对RV、谐波减速器的需求,线性执行器中需要用到行星滚柱丝杠作为线性传动装置。
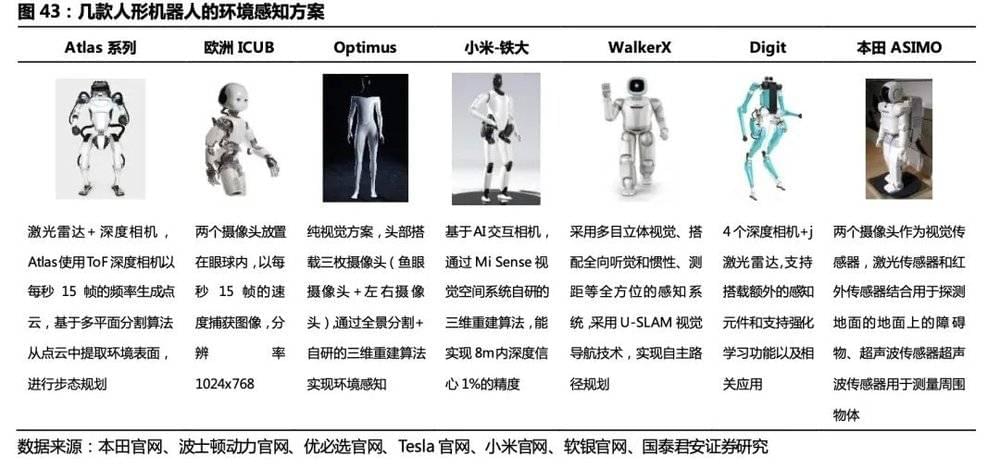
3)环境感知:区别工业机器人在固定场景外接机器视觉设备实现识别的方案,人形机器人场景复杂,需采用激光雷达、摄像头等方案实现环境感知、三维重建并实现路径规划,对设备品类、算法、实时算力要求更高。
4)运动控制:类似于工业机器人,运控算法均是厂商自研,开发难度大,是核心竞争力之一;特斯拉Optimus复用特斯拉汽车的感知和计算能力,在全自动驾驶FSD芯片基础上开发适合人形机器人的控制器系统。人形机器人传感器数量、品类、执行机构复杂程度远高于工业机器人,对控制器实时算力、集成度要求高。
一、通用——解决机器人高需求和低渗透率的矛盾
1.1.机器人进化路径:从固定到移动,从独立到协作,从单一到通用
服务机器人商业化落地的前提是产品能提供真实价值,真实价值的判断在于机器人能否通用。在全球劳动力短缺的背景下,机器人产业蓬勃发展,2022年全球服务机器人市场规模217亿美元,过去5年复合增速超过20%。然而,在高速发展背景下,服务机器人渗透率仍然不高,规模化商业落地并不顺利。
我们认为原因在于: 目前大多数服务机器人都或多或少地存在场景适应性的问题, 如无法适应环境变化,环境变化后,用户无法通过简单操作实现场景适配;智能化程度低,行人避障及功能表现不理想;机器人部署流程复杂(如SLAM建图、目标点标注等),所有部署操作只能由机器人现场部署工程师执行,使用者难以操作及参与,且当需要变更时,仍需现场部署工程师进行操作。以商超场景为例:
环境复杂:场景中镂空的货架(超高类障碍物)、狭窄的通道、易跌落区域、低矮类障碍物及临时的摊铺,考验机器人的通过性、感知能力、任务规划能力。
高动态化:商场人流大,易聚集,动态障碍物多,对机器人安全避障能力要求高。
特殊物体较多,场景光线变化大:如玻璃护栏、自动扶梯、玻璃转门、玻璃墙等高透物体大多数机器人基本无法识别,且容易对激光雷达产生干扰,导致机器人误判,发生碰撞、跌落、无法靠近作业。对于依赖视觉传感器的机器人来说,要在普通光线、黑暗、过曝等光照条件都能稳定运行难度较大。
以上问题在工业机器人领域同样存在,影响了工业机器人渗透率的提升,直到协作机器人的出现。2022年全球协作机器人市场规模89.5亿元人民币,预计2022~2028年市场规模将以22.05%的增速达到300亿元。2017~2022年中国协作机器人销量从3618台增长至19351台,预计2023年出货将超过2.5万台,2016~2021年市场规模从3.6亿人民币增长至20.39亿人民币,复合增速41.5%。
协作机器人也可以被认为是服务机器人,因为他们旨在与人类并肩作战。传统工业机器人在栅栏后与人分开作业,完成的工作也有限,例如焊接、喷涂、吊装等。协作机器人更灵活,更智能,更容易合作,更具有适应能力,使汽车、电子等制造行业能够将自动化扩展到最终产品组装,完成任务(例如抛光和施涂涂层)以及质量检查等等。
1.2.如何让机器人更加通用?
使机器人更加通用,需要机器人的感知能力、思考和决策能力、行动执行能力的全面提升。我们认为GPT(预训练大预言模型)和人形机器人的出现,是机器人在迈向通用人工智能的道路上的一大步。
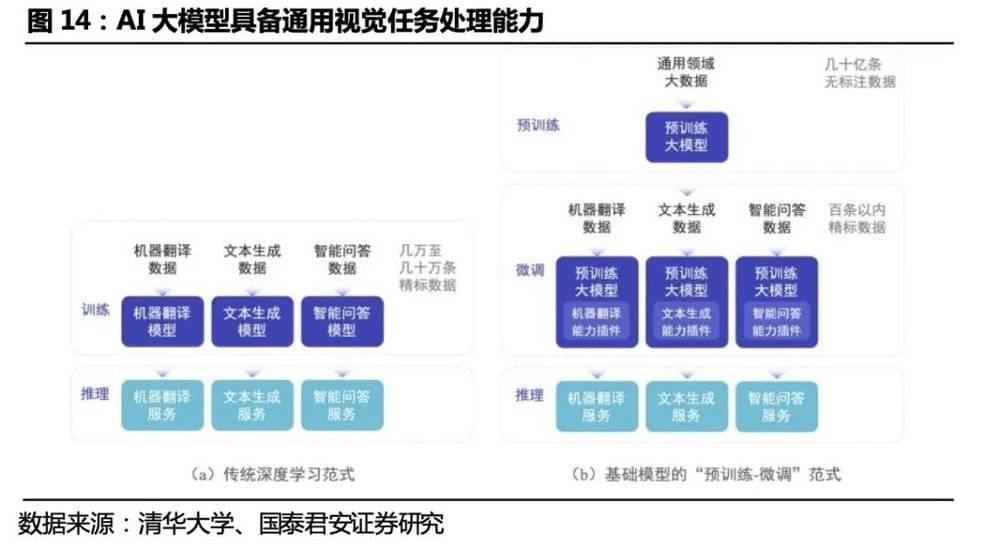
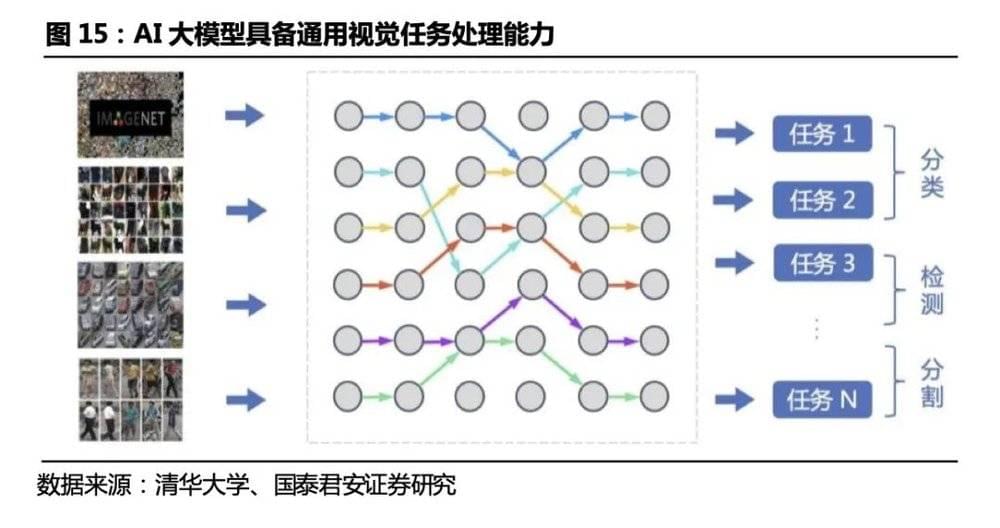
感知世界的能力 (机器人的眼睛) : 机器人自主移动的感知和定位技术中激光和视觉导航是主流应用方案。计算机视觉的发展经历了基于以特征描述子代表的传统视觉方法、以CNN卷积神经网络为代表的深度学习技术,目前通用的视觉大模型正处于研究探索阶段,人形机器人的场景相对工业机器人更通用、更复杂,视觉大模型的All in One 的多任务训练方案能使得机器人更好地适应人类生活场景。一方面,大模型的强拟合能力使得人形机器人在进行目标识别、避障、三维重建、语义分割等任务时具备更高的精确度;另一方面,大模型解决了深度学习技术过分依赖单一任务数据分布,场景泛化效果不佳的问题,通用视觉大模型通过大量数据学到更多的通用知识,并迁移到下游任务中,基于海量数据获得的预训练模型具有较好的知识完备性,提升场景泛化效果。
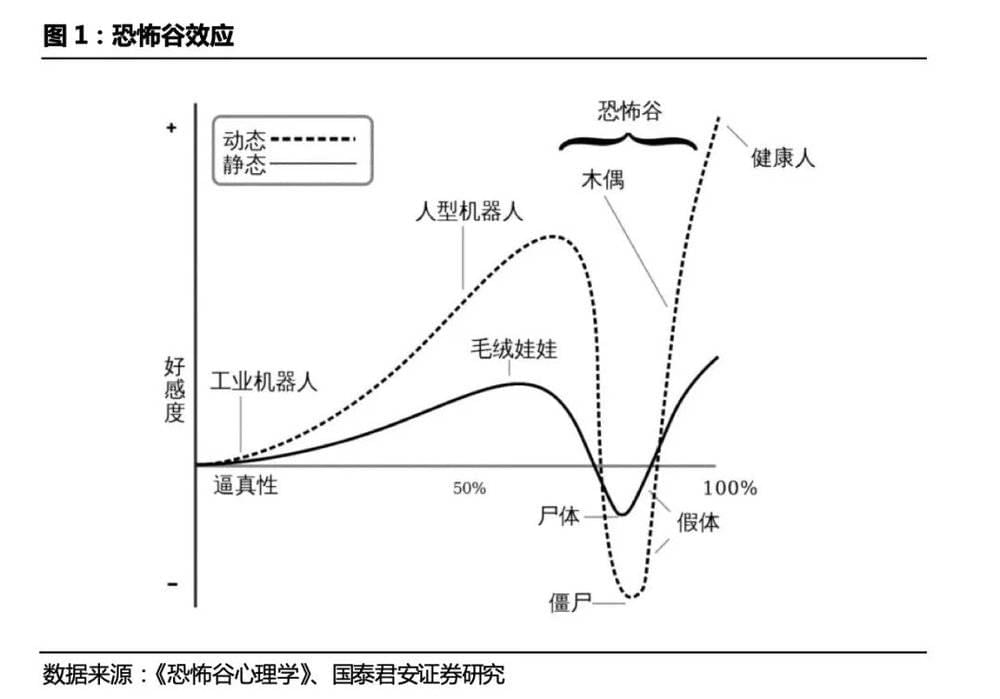
思考和决策的能力 (机器人的大脑) : 目前的机器人都是专用机器人,只能在限定场景中应用,即使是机器人抓取,基于计算机视觉,仍然是在限定场景中,算法仅用于识别物体,如何做、做什么仍需要人的定义。要让机器人通用,叫他去浇花,他就知道去拿水壶,接水,然后浇花,这是需要常识才能完成的事情。如何能让机器人拥有常识?在大模型出现之前,这个问题几乎是无解的。大模型让机器人可以拥有常识,从而具备通用性去完成各种任务,彻底改变通用机器人实现的模式。 人类工具和环境的适应性,不用再为了机器人而造工具。执行能力 (机器人的四肢) : 行动能力(腿)+精细操作(手)。把机器人做成人形,就是为了让机器人的执行能力更加通用。机器人执行任务时所处的环境是按照人类的体型建造起来的:建筑、道路、设施、工具等,这个世界是为了方便人类这种人形生物才这样设计。如果出现了某种新形态的机器人,人们就必须重新设计一套机器人适应的全新环境。设计在某个特定范围内执行任务的机器人相对容易,如果想要提高机器人的通用性,就必须选择可以作为分身的人形机器人。此外,人类与人形机器人更容易有情感上的交流,人形机器人会让人感到亲近。日本机器人专家森昌弘的假设指出:由于机器人与人类在外表、动作上相似,所以人类亦会对机器人产生正面的情感。
1.3.人形机器人进入商业化前夜
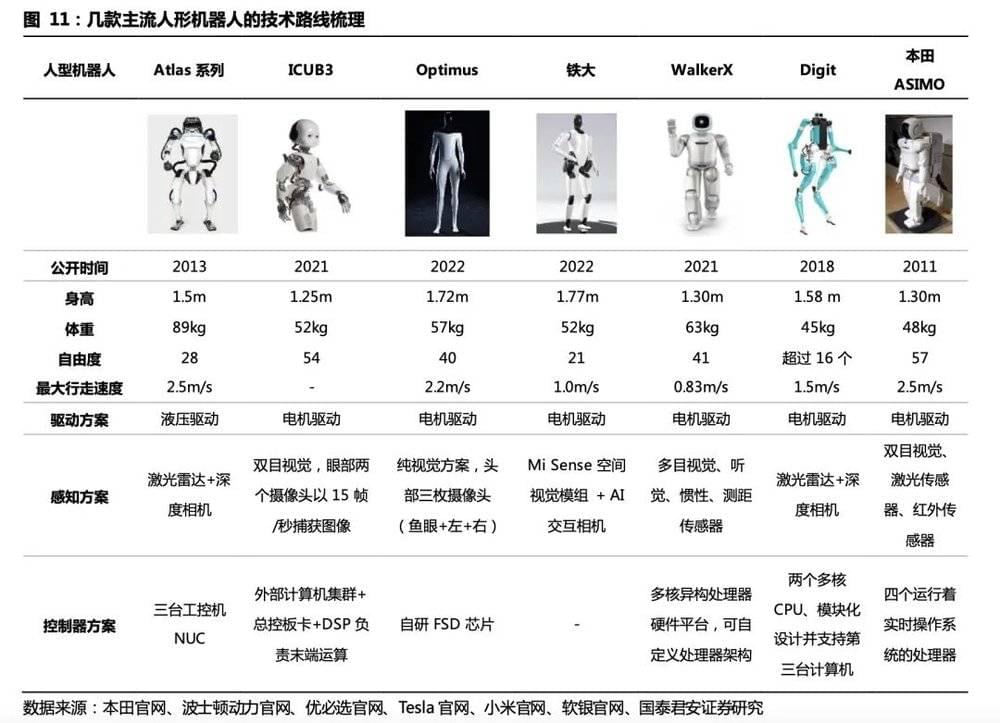
从2015年DARPA Robotics Challenge,到2019年人形机器人各种科研项目被砍,业内普遍唱衰,再到2022年特斯拉带动的百花齐放,人形机器人产业处于螺旋式向上的发展之中。波士顿动力的Atlas、Tesla的Optimus、小米CyberOne、ihmc的Nadia,Agility Robotics的Nadia、日系Asimo与HRP-5P都在探索人形机器人的商业形态。我们对人形机器人发展过程中有代表性的产品进行了梳理:
第一台人形机器人WABOT-1 (1973年) 。 1973年日本早稻田大学加藤一郎带领团队研发出世界上第一台真人大小的人形智能机器人——WABOT-1。该机器人有肢体控制系统、视觉系统和对话系统,胸部装有两个摄像头,手部装有触觉传感器。 本田E系列机器人 (1986~1993年) ,奠定稳定行走基础。 本田推出E系列双足机器人,E0到E6,走路速度由慢变快,从走直线到在台阶或坡地上均可实现稳定行走,为下一步P系列类人机器人的研发奠定了基础,是机器人历史的里程碑。 本田P系列机器人 (1993-1997年) &ASIMO (2000~2011) 。 1993年本田开发第1个仿人机器人原型P1,2000年P系列中的第4台也是最后一台机器人P4诞生,通俗称呼阿西莫(ASIMO)。2011年推出的第三代ASIMO身高1.3米,体重48公斤,行走速度是0-9km/h,2012最新版的ASIMO,除具备了行走功能与各种人类肢体动作之外,还可以预先设定动作,并依据人类的声音、手势等指令,做出相应动作。他还具备了基本的记忆与辨识能力。2018年本田宣布停止人形机器人ASIMO的研发,专注于该技术的更多实际应用。
HPR系列机器人 (1998~2018) 代替建筑行业的繁重工作: 这是由日本经济产业省和新能源与产业技术开发组织赞助,川田工业株式会社(Kawada Industries)牵头与国立先进工业科学技术研究院(AIST)和川崎重工株式会社共同研发的通用家庭助手机器人的开发项目。项目起始于1998年HPR-1(Honda P3),先后推出了HPR-2P、HRP-2、HRP-3P、HRP-3、HRP-4C、HRP-4等多个人形机器人。目前最新的机器人HPR-5P于2018年发布,该机器人身高182cm,体重101kg,全身总共37个自由度,旨在替代建筑行业中的繁重工作。
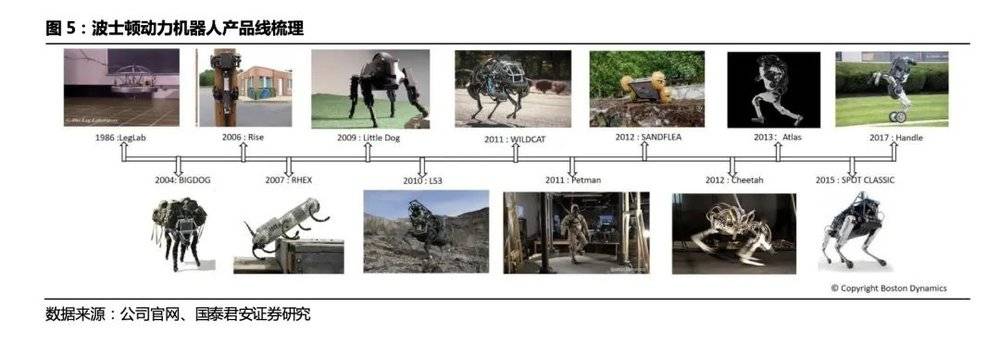
波士顿动力 (1986~2023) : 腿足式机器人运控技术最前沿,军事化应用特征明显。 波士顿动力最早因研发的Big Dog而被世界闻名,公司发布了BigDog、Rise、LittleDog、PETMAN、LS3、Spot、Handle、Atlas等多个机器人,从单足、多足机器人到人形机器人,有着明显的军事化应用的路线特征。波士顿动力是一家典型的技术驱动的公司,从机械结构、算法步态控制、动力系统耗能等方面对机器人持续迭代更新,核心在于发展腿式机器人以适应不同环境的使用,技术关键在于动力学研究和机器人平衡态的控制。
Digit系列机器人 (2019~2023) :具备行走能力,专注物流领域商业化。 Digit系列是Agility Robotics公司在物流领域商业化的尝试,公司是从俄勒冈州立大学(OSU)拆分出来的机器人公司,致力于研发和制造双足机器人,前后开发了MABEL、ATRIAS、CASSIE、DIGIT系列足式机器人。其中CASSIE可实现4m/s的惊人配速,是腿足式机器人在快速行走能力上里程碑式的成果。2019年,Agility推出了人形机器人Digit,在Cassie的基础上加上了躯干、手臂,并增加了更多计算能力,支持负载18kg的箱子,可进行移动包裹、卸货等工作。
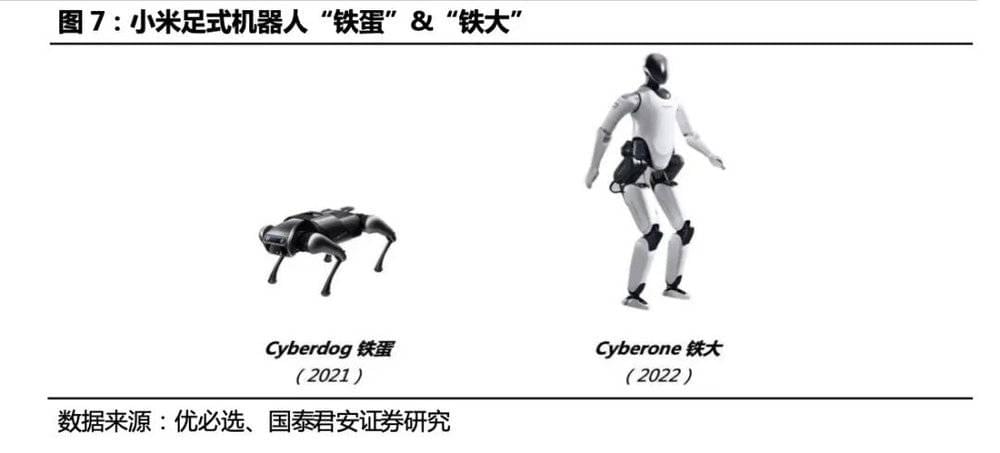
小米“铁大”机器人 (2022) :21年小米曾发布一款机械狗Cyberdog,是其在足式机器人的首次尝试。 2022年8月,小米首个全尺寸人形仿生机器人 CyberOne 亮相秋季发布会。CyberOne 身高 177cm,体重 52kg,艺名“铁大”,能感知 45 种人类语义情绪,分辨 85 种环境语义;搭载小米自研全身控制算法,可协调运动 21 个关节;配备了 Mi Sense 视觉空间系统,可三维重建真实世界;全身 5 种关节驱动,峰值扭矩 300Nm。
特斯拉Optimus机器人 (2022年) :推动人形机器人商业化。 Optimus原型机亮相于2022年特斯拉AIday,身高1.72m,体重 57kg,可负载 20kg,最快运动速度 8km/h。目前Optimus仍处于研发进展迅速,仅8个月机器人已可实现直立行走、搬运、洒水等复杂动作。
交互型机器人索菲亚 (2015) 和阿梅卡 (2021) ,面部表情拟人化的尝试: 索菲亚(Sophia)是由汉森机器人技术公司(Hanson Robotics)开发的类人机器人,2015年面世。索菲娅皮肤由Frubber仿生材料制成,基于语音识别、计算机视觉技术,可以识别和复制各种各样的人类面部表情,并通过分析人类表情和语言同人类对话。阿梅卡(Ameca)由英国领先的仿生娱乐机器人设计和制造公司——工程艺术有限公司(Engineered Arts)打造,具有12个全新的面部致动器,经过面部表情升级后,能对着镜子眨眼、抿嘴、皱眉、微笑。阿梅卡能够自由进行几十种仿人类的肢体运动,被认为是“世界上最逼真机器人”。
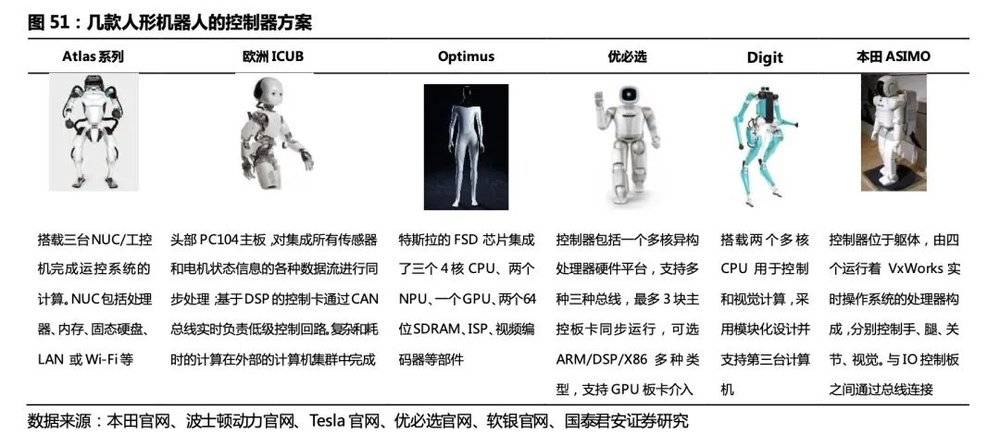
我们选择了7款有代表性的人形机器人,从驱动、感知、控制器三个方面进行技术路线梳理。
二、AI大模型+人形机器人:给机器人提供常识
2.1.AI大模型训练过程及发展趋势
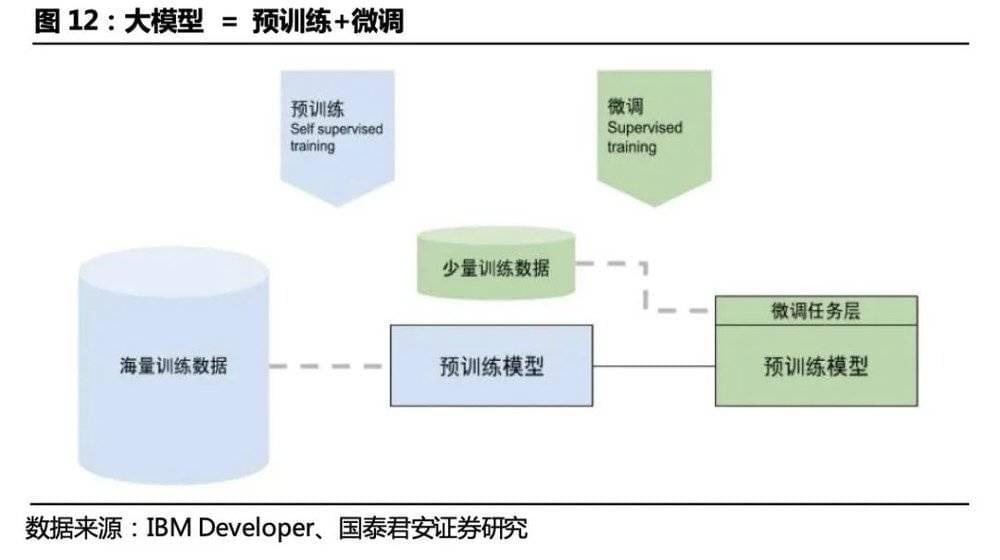
大模型=预训练+微调。 从2017年Transformer开始,到GPT-1、BERT、GPT-2、GPT-3、GPT-4模型的出现,模型的参数量级实现了从亿到百万亿量级的突破,大模型(预训练模型、Foundation Models)在无标注的数据上进行预训练,利用专用的小规模的标注数据对模型进行微调(fine-tuning),可用于下游任务预测。迁移学习是预训练模型的主要思想,当目标场景数据不足时,先在数据量大的公开数据集上训练基于深度神经网络的AI模型,然后将其迁移到目标场景中,通过目标场景中的小数据集进行微调,使模型达到要求的性能。预训练模型极大地减少了模型在标记数据量下游工作的需要,从而适用于一些难以获得大量标记数据的场景。
大模型的发展过程和趋势:从参数规模上看,大模型经历了从预训练模型、大规模预训练模型、超大规模预训练模型的阶段,参数量实现了从亿级到百万亿级的发展。从数据模态来看,大模型正在从文本、语音、视觉等单一模态大模型,向着多种模态融合的通用人工智能方向发展。
2.2.AI大模型让人形机器人具备通用任务解决能力
AI大模型将会从语音、视觉、决策、控制等多方面实现同人形机器人的结合,形成感知、决策、控制闭环,大大提升机器人的“智慧”程度:
语音: ChatGPT作为一种预训练语言模型,可以被应用于机器人与人类之间的自然语言交互。例如,机器人可以通过ChatGPT来理解人类的自然语言指令,并根据指令进行相应的动作。自然语言是人类最通用的交互媒介,语音作为自然语言的载体将会是机器人拟人化的关键任务。尽管深度学习的出现已经将以语音识别技术、自然语言处理、语音生成技术为构成模块的语音交互技术推向相对成熟的阶段,但实际过程中仍然容易出现语义理解偏差(反讽等)、多轮对话能力不足、文字生硬的情况。语言大模型为机器人的自主语音交互难题提供了解决方案,在上下文理解、多语种识别、多轮对话、情绪识别、模糊语义识别等通用语言任务上,ChatGPT表现出了不亚于人类的理解力和语言生成能力。在以ChatGPT为代表的大模型的加持下,人形机器人对通用语言的理解和交互才能提上日程,这将会是通用AI赋能通用服务机器人的开始。
视觉: 视觉大模型赋能人形机器人识别更精确,场景更通用。计算机视觉的发展经历了基于以特征描述子代表的传统视觉方法、以CNN卷积神经网络为代表的深度学习技术,目前通用的视觉大模型正处于研究探索阶段。一方面,大参数量模型的强拟合能力使得人形机器人在进行目标识别、避障、三维重建、语义分割等任务时具备更高的精确度;另一方面,通用大模型解决了过去以卷积神经网络为代表的深度学习技术过分依赖单一任务数据分布,场景泛化效果不佳的问题,通用视觉大模型通过大量数据学到更多的通用知识,并迁移到下游任务中,基于海量数据获得的预训练模型具有较好的知识完备性,大大提升场景泛化效果。人形机器人的场景相对工业机器人更通用、更复杂,视觉大模型的All in One 的多任务训练方案能使得机器人更好地适应人类生活场景。
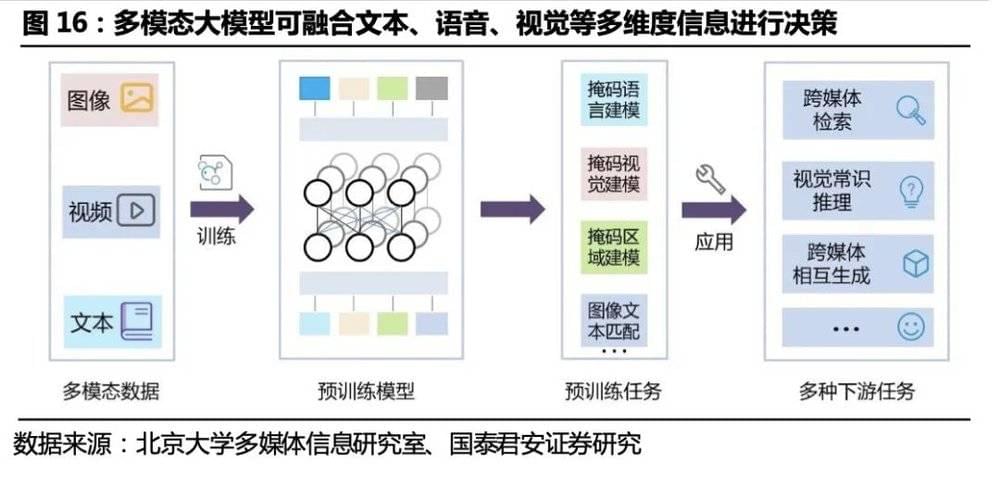
决策: 通用语言、环境感知能力是自动化决策的基础,多模态大模型契合人形机器人的决策需求。单一模态智能无法解决设计多模态信息的决策问题,如“语音告知机器人去取桌子上绿色苹果”的任务。多模态统一建模,目的是增强模型的跨模态语义对齐能力,使模型逐步标准化,使得机器人能综合视觉、语音、文本多维度信息,实现各感官融合决策的能力。基于多模态的预训练大模型或将成为人工智能基础设施,增强机器人可完成任务的多样性与通用性,让其不只局限于文本和图像等单个部分,而是多应用相容,拓展单一智能为融合智能,使机器人能结合其感知到的多模态数据实现自动化决策。
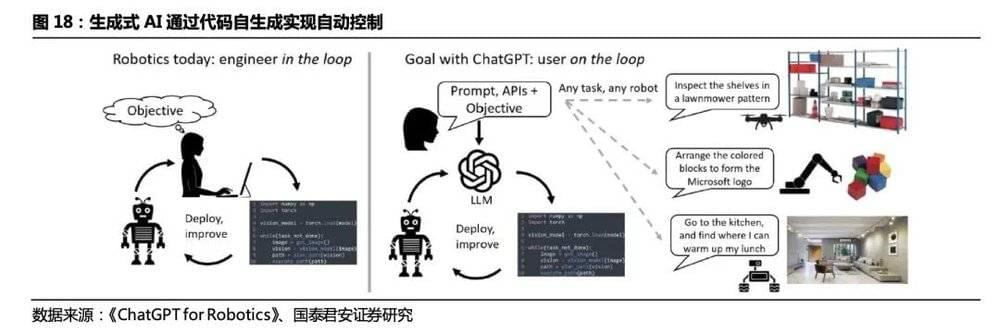
控制: 生成式AI赋能机器人自我控制,最终形成感知、决策、控制闭环。使得人形机器人具备通用能力,首先需要其具备“常识”,即通用的语言理解能力(语音)和场景理解能力(视觉);其次需要其具备决策能力,即接收指令后产生的对任务的拆解;最后,需要其具备自我控制和执行性能,生成式AI的代码生成能力将最终使得机器人的感知、决策、动作形成闭环,达到自我控制的目的。事实上,近来微软团队已经尝试将ChatGPT应用于机器人控制的场景中,通过提前写好机器人底层函数库,并对其描述功能作用及目标,ChatGPT能生成完成任务的代码。在生成式AI的推动下,机器人编程的门槛将会慢慢降低,最终实现自我编程、自我控制,并完成人类习以为常的通用任务。2.3.OpenAI和微软将大语言模型应用于机器人
OpenAI领投挪威人形机器人公司1X Technologies。2017年OpenAI推出了用于机器人的开源软件Roboschool,在机器人中部署了新的单样本模仿学习算法,通过人类在VR中向机器人演示如何执行任务。2018年,OpenAI发布了8个模拟机器人环节和事后经验回访基线实施,并用来训练在物理机器人上工作的模型。22年,Halodi Robotics在挪威Sunnaas医院测试了医护助理机器人EVE,让其执行后勤工作。2023年3 月 28 日,OpenAI领投挪威人形机器人公司1X Technologies(前称 Halodi Robotics)。Halodi Robotics通过Ansys初创公司计划利用Ansys仿真软件开发能在日常场景中与人安全协作的人形机器人。
微软提出ChatGPT for Robotics,利用ChatGPT解决机器人应用程序编写问题。2023年4月,微软在其官网发表了一篇名为《机器人ChatGPT:设计原则和模型能力(ChatGPT for Robotics: Design Principles and Model Abilities)》的论文,这项研究的目标是观察ChatGPT是否可以超越文本思考,并对物理世界进行推理来帮助完成机器人任务。人类目前仍然严重依赖手写代码来控制机器人,该团队一直在探索如何改变这一现实,使用OpenAI的新人工智能语言模型ChatGPT实现自然的人机交互。
人类可以从机器人流程中的inthe loop变为onthe loop。 论文提出,不要求LLM输出特定于机器人平台或者库的代码,只是创造简单的高级函数库供ChatGPT调用,并在后端将高级函数库链接到各个平台,场景和工具的现有库和API。结果证明,ChatGPT的引入,使得人类通过自然语言等高级语言命令与语言模型交互,用户通过文本对话不断将人类的感知信息输入ChatGPT,ChatGPT解析观察流并在对话系统中输出相关操作,不需要生成代码。这样,人类可以实现无缝部署各种平台和任务,人类对ChatGPT输出的质量和安全性进行评估。 人类在机器人pipeline中的任务主要是: 1)首先,定义一组高级机器人API 或函数库。 该库可以针对特定的机器人类型进行设计,并且应该从机器人的控制栈或感知库映射到现有的低层次具体实现。为高级API 使用描述性名称非常重要,这样 ChatGPT 就可以推理它们的行为。 2)为ChatGPT 编写一个文本提示,描述任务目标,同时明确说明高级库中的哪些函数可用。 提示还可以包含有关任务约束的信息,或者ChatGPT 应该如何组织它的答案,包括使用特定的编程语言,或使用辅助解析组件等。 3)用户通过直接检查或使用模拟器来评估ChatGPT 的代码输出。 如果需要,用户使用自然语言向ChatGPT 提供有关答案质量和安全性的反馈。4)当用户对解决方案感到满意时,就可以将最终的代码部署到机器人上。
ChatGPT可以以zero-shot的方式解决简单的机器人任务。对于简单的机器人任务,用户只需要提供文本提示和函数库描述,不需要提供具体的代码实例,ChatGPT就可以zero-shot解决时空推理(ChatGPT控制一个平面机器人,用视觉伺服捕捉篮球位置)、控制真实无人机完成物体寻找、操纵虚拟无人机实现工业检测等问题。
在人类用户onthe loop交互下,ChatGPT可以完成更复杂的机器人控制任务。1)课程学习:教授ChatGPT简单的拾取和放置物体的技能,并将所学会的技能按照逻辑组合用于更复杂的区块排列任务;2)Airsim避障:ChatGPT构建了避障算法的大部分关键模块,但需要人工反馈无人机朝向等信息。人工反馈高级的自然语言,ChatGPT能够理解并在适当的位置进行代码修正。
ChatGPT的对话系统能够解析观察并输出相关操作。1)带API的闭环对象导航:为ChatGPT提供了对计算机视觉模型的访问,作为其函数库的一部分。ChatGPT在其“代码”输出中构建感知-动作循环,实现估计相对物体角度、探索未知环境、并导航到用户指定对象的功能;2)使用ChatGPT的对话系统进行闭环视觉语言导航。在模拟场景下,人类用户将新的状态观测值作为对话文本输入,ChatGPT的输出仅返回向前的运动距离和转弯角度,实现了用“对话系统”指导机器人一步步导航到感兴趣区域。
三、人形,让机器人的运动执行更加通用
执行能力 (机器人的四肢) :行动能力 (腿) +精细操作 (手) 。把机器人做成人形,是为了让机器人的执行能力更加通用。 机器人执行任务时所处的环境是按照人类的体型建造起来的:建筑、道路、设施、工具等,这个世界是为了方便人类这种人形生物才这样设计。如果出现了某种新形态的机器人,人们就必须重新设计一套机器人适应的全新环境。设计在某个特定范围内执行任务的机器人相对容易,如果想要提高机器人的通用性,就必须选择可以作为分身的人形机器人。本章选择两个代表性产品波士顿动力Altas和特斯拉Optimus,从驱动、环境感知、运动控制三方面对比方案差异,探寻人形机器人运动控制方案商业化的趋势。波士顿动力Altas定位于技术的前瞻性研究,侧重探索技术应用的可能性而非商业化。从硬件架构来看,Altas具备出色的动态性能、瞬时功率密度和稳定的运动姿态,可以实现高负载、高复杂度的运动, 像是一场技术驱动的盛宴。商业化并非波士顿动力当前主要考量因素,Altas项目更多作为一个研究平台供研究者进行学术试验,侧重探索技术应用的可能性而非商业化。
特斯拉Optimus发心于人形机器人的规模化、商业化、标准化,商业化的目标驱动下,成本、能耗成为特斯拉团队的考量指标。
3.1.驱动:液压驱动VS电动驱动
3.1.1.电驱成本低、易于维护、控制精度高,商业化潜力高主流人形机器人的驱动方案包括液压驱动和电气驱动(伺服电机+减速器)两种。相比电气驱动,液压驱动输出力矩大、功率密度高和过载能力强,因而能满足波士顿动力Atlas高负载动作和快速运动的需求;但液压驱动的方式能耗大、成本高,同时容易出现漏液等问题、可维护性差。一方面,商用场景下高负载动作(如跑酷、后空翻等)属于非必要行为,另一方面,随着电驱系统功率密度和响应速度的不断提升,我们认为结合电驱成本低、易于维护且技术应用成熟的优势,基于电驱的人形机器人商业化可能性更高。
3.1.2.波士顿动力Atlas:采用“液压驱动”方案波士顿动力全身共28个液压执行器,可执行高负载复杂动作。HPU(Hydraulic Power Unit)作为Atlas的液压动力源具备极小尺寸的高能量密度(~5kW/5Kg),电液经由流体管线连接至各液压泵,可实现快速响应和精确力控,其高瞬时功率密度的液压驱动器能支持机器人实现奔跑、跳跃、后空翻等复杂动作,机器人的结构强度得益于其高集成度的结构总成。根据官方披露影像及专利细节,我们推测:踝、膝、肘关节由液压缸驱动;髋、肩、腕关节及腰腹由摆动液压缸驱动。
3.1.3.特斯拉Optimus:采用“电动驱动”方案单台Optimus全身40个执行器,是单台多关节机器人的6~7倍。其中:身体关节部分采用减速器/丝杆+伺服电机的传动方式,共计28个执行器;机械手基于欠驱动方案,采用电机+腱绳驱动(tendon-driven)的传动结构,单手6个电机,11个自由度。
根据TestlaAIDay,特斯拉自主研发的六种执行器中,旋转关节方案继承工业机器人,线性执行器和微型伺服电机是人形机器人新需求,具体看:
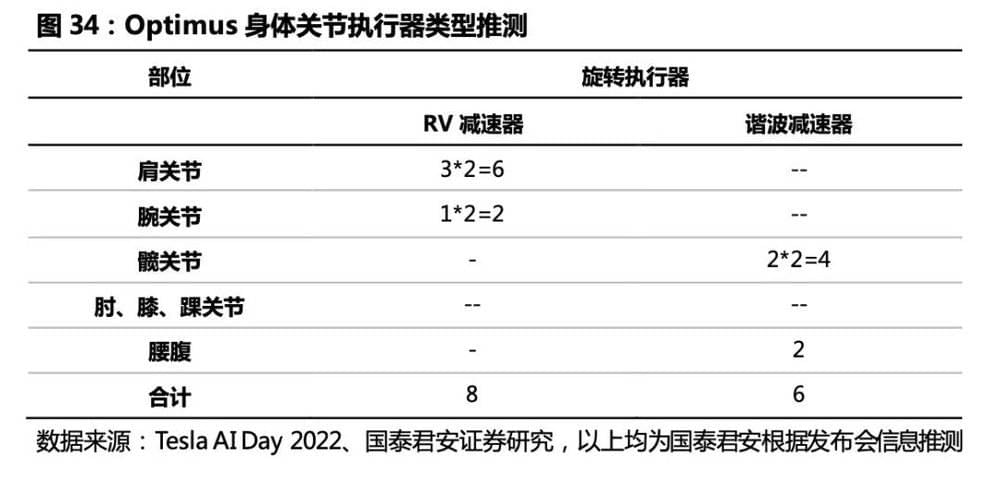
旋转关节方案 (肩、髋、腰腹) :伺服电机+减速器, 我们推测,单台人形机器人将搭载6台RV减速器(髋、腰腹)和8台谐波减速器(肩、腕)。根据特斯拉Optimus执行器方案,RV减速器体积大、负载能力强、刚度高,适用于髋、腰腹大负载关节,其中髋关节2*2台、腰腹两个自由度2台,共计6台;谐波减速器体积小、传动比高、精密度高,适用于肩、腕关节,其中肩关节3*2台、腕关节1*2台,共计8台。随着更多厂商的涌入,其执行器方案可能存在差异,若线性执行器被旋转执行器替代,单台机器人减速器数量将有所提升。
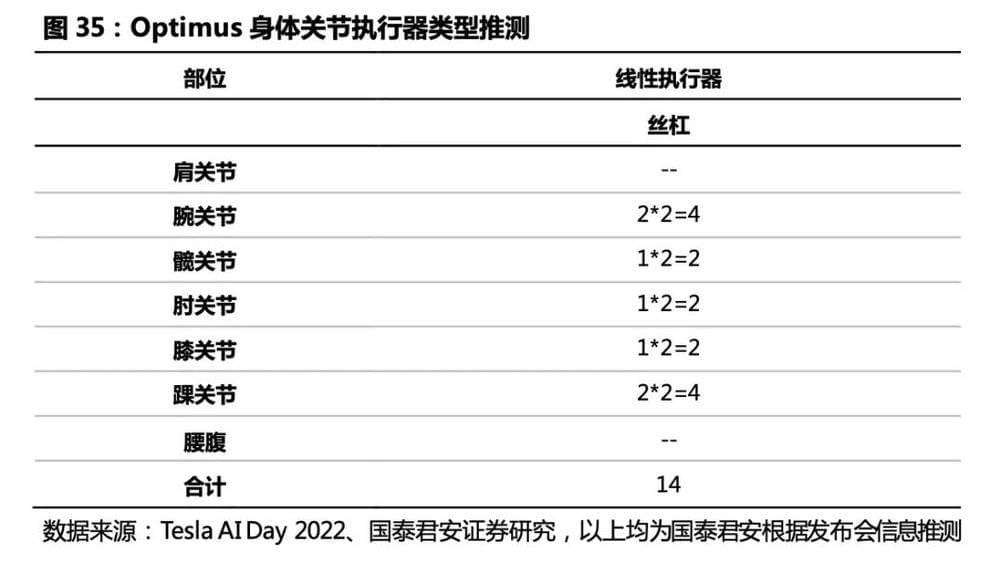
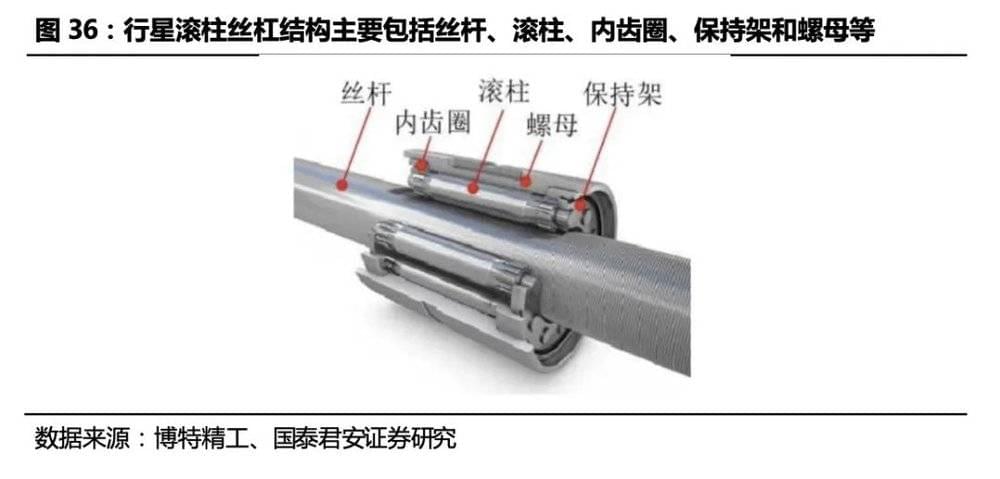
摆动角度不大的关节 (膝、肘、踝、腕) :线形执行器 (伺服电机+丝杠) 。 一体化伺服电动缸(伺服电机+丝杠)方案具备自锁能力,能耗比纯旋转关节方案低。线性执行器空间利用率高、能提供较大的推动力。我们猜测,线性执行器基于力矩电机结合行星滚柱丝杠的方案将应用于线性执行器关节(髋、膝、踝、肘、腕)中,预计合计将使用14个线性执行器。
行星滚柱丝杠以其高承载、高刚度、长寿命的特点或成为人形机器人线性执行器的关键传动装置,通过适配人形机器人需求实现降本是大规模放量的前提。根据TeslaAIDay2022会上展示的信息来看,Optimus线性执行器采用的方案即为行星滚柱丝杠一体式伺服电动缸。我们认为下肢髋、膝、踝关节及上肢的肘关节的伺服电缸采用高承载、高刚度的行星滚柱丝杠作为传动装置可能性比较大。行星滚柱丝杠结构复杂、加工难度大因而成本很高,通过调整设计、工艺方案适配人形机器人的需要来实现降本是其大规模应用的前提。
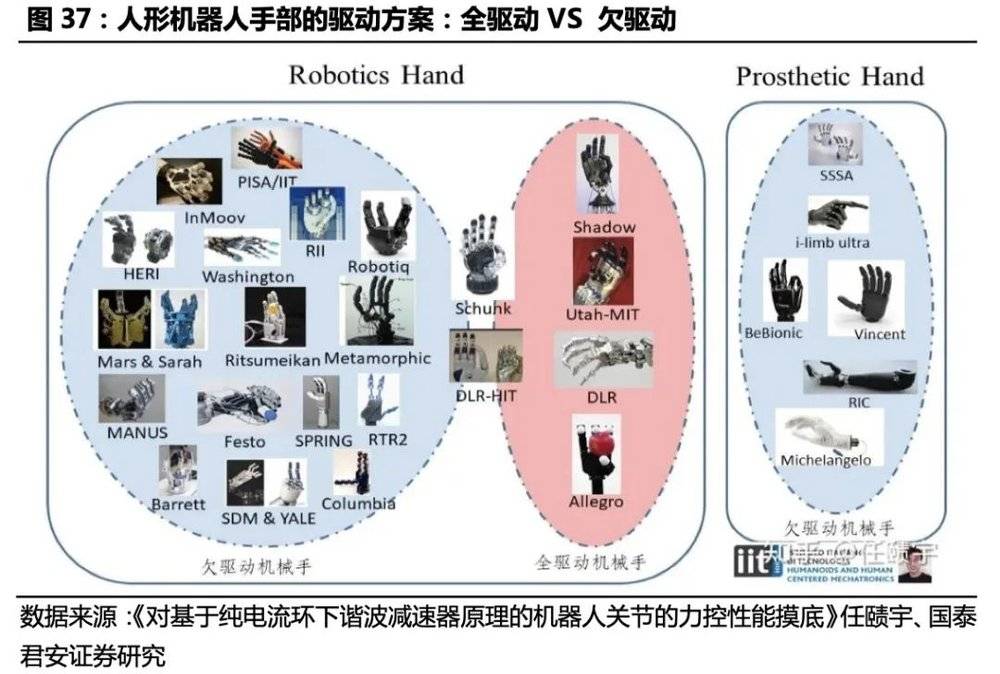
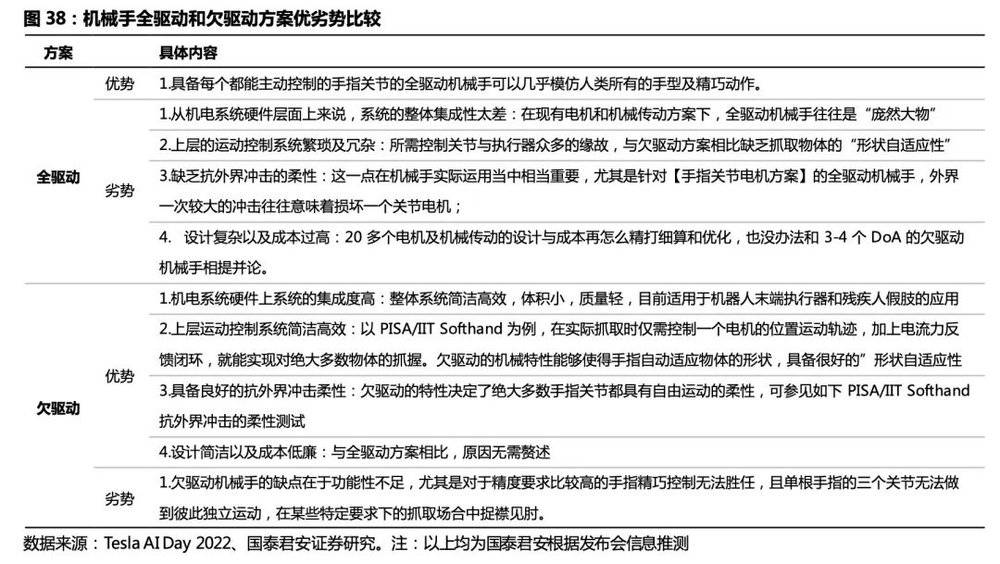
机械手:Optimus单手包括6个执行器,可实现11个自由度,由微型电机驱动,“欠驱动”方案性价比高,“绳驱”传动结构不确定性较大。“欠驱动”,系统执行器的数目小于其自由度数目,因为机械手本身高自由度数目的特性,出于提高系统设计的集成性、紧凑性和降低成本、更出于简化后续运动控制的考虑,设计者们会减少所使用电机的数目(即执行器的数目),形成了执行器的数目小于其自由度数目的欠驱动方案。通过机械结构的优化实现以较少的执行机构驱动更多的自由度,节省成本,是目前商业产品及高效机械手研发的主流选择。
机械手驱动方案差异较大,电机的轻量化、低成本是关键。 机械传动结构上,机械手的主流方案包括绳驱(TendonDriven)、连杆、齿轮齿条、材料形变等。各机械手驱动方案差异很大:Ritsumeikan HandRitsumeikan Hand通过耦合走线实现了2个驱动器对15个关节的驱动;Stanford/JPL灵巧手单手16个电机;ShadowHand单手30个电机,合计24个自由度。人形机器人机械手需要满足质量轻、结构紧凑和抓取力强的要求,因此电机应具有尺寸小、质量轻、精度高、扭矩大的特点。空心杯电机结构紧凑、能量密度高、能耗低,和人形机器人机械手需求契合度高。
特斯拉Optimus机械手采取电机+腱绳驱动的方式,可能对手部传动方案进行优化。尽管绳驱给机械手带来了极大的灵活性,且可以极大简化设计难度和系统的复杂性,但其可靠性、传动效率都低于传统连杆、齿轮齿条等方式,可能是研发团队短期开发的权宜之计。
3.2.环境感知:深度相机+激光雷达 VS纯视觉方案
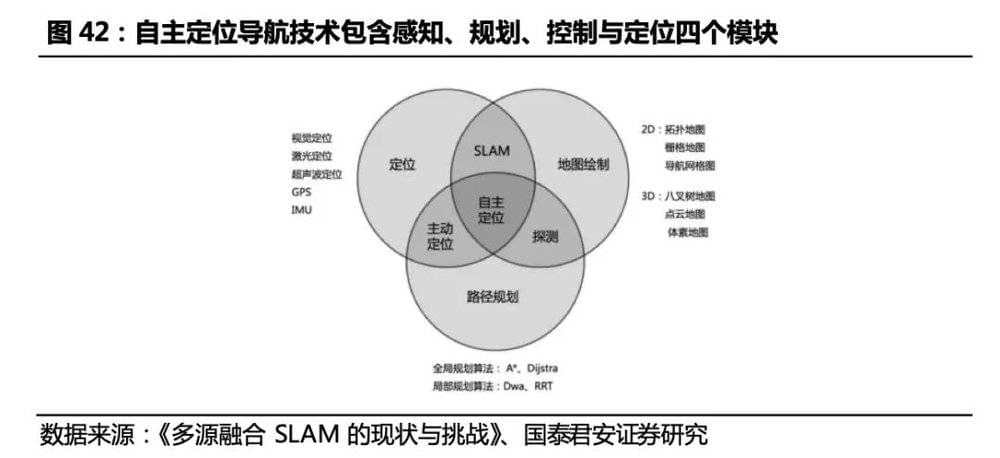
用于实现机器人自主移动的感知和定位技术原理主要包括视觉、激光、超声波、GPS、IMU等,对应机器人感知系统的不同传感器类别。SLAM(即时定位与地图构建)是发展比较成熟、应用广泛的定位技术,它是机器人通过对各种传感器数据进行采集和计算,生成对其自身位置姿态的定位和场景地图信息的系统。SLAM问题可以描述为:机器人在未知环境中从一个未知位置开始移动,在移动过程中根据位置估计和传感器数据进行自身定位,同时建造增量式地图。获取定位和地图后,再根据路径规划算法(全局、局部、避障)实现自主移动。
3.2.1.波士顿动力Atlas:深度相机+激光雷达波士顿动力Atlas感知方案融合深度相机和激光雷达,基于多平面分割算法实现步态规划。Atlas机器人感知视觉技术发展相对成熟,它借鉴Google Transformer模型,搭建HydraNet神经网络模型,优化视觉算法,完成了自动驾驶纯视觉系统的迁移; Atlas使用ToF深度相机以每秒 15 帧的频率生成点云,基于多平面分割算法从点云中提取环境表面,数据经过映射后完成对周边物体的识别。之后,工控机基于识别到的表面和物体信息进行步态规划,以实现避障、探测地面状况和巡航等任务。IHMC全称为“人类与机器认知研究所”,是一家专注于研发机器人控制算法的顶尖机构,主要研发人形机器人行走所需的关键算法,而指挥Atlas机器人站立、行走等算法就来自于IHMC。
3.2.2.特斯拉Optimus:纯视觉方案,成本更低特斯拉Optimus环境感知采用基于摄像头的纯视觉方案,移植特斯拉全自动驾驶系统,成本更低。Optimus头部搭载三枚摄像头(鱼眼摄像头+左右摄像头),通过全景分割+自研的三维重建算法(Occupancy Network)实现环境感知,纯视觉方案相比激光雷达等感知设备成本更低,但对算力要求高。机器人继承了Autopilot算法框架,通过重新采集数据训练适用于机器人的神经网络,以实现环境的三维重建、路径规划、自主导航、动态交互等。特斯拉强大的全自动驾驶系统(FSD)的移植,使机器人视觉方案在不增加硬件成本的前提下朝着更精确、更智能的方向进步。
3.3.运动控制:尚未形成通用的控制器解决方案
运控算法是核心竞争力,各家人形机器人控制算法均为自研。人形机器人对运动控制能力及感知计算能力要求较高,且不同厂商的执行器数量和类别差异较大,未来运控算法或成为厂商核心竞争力,且自研可能性较大;此外人形机器人控制方案,对于客户应用场景的了解程度及工艺要求也是重要因素,目前下游场景分散,单独一家厂商还很难将人形机器人做到各个场景的通用。
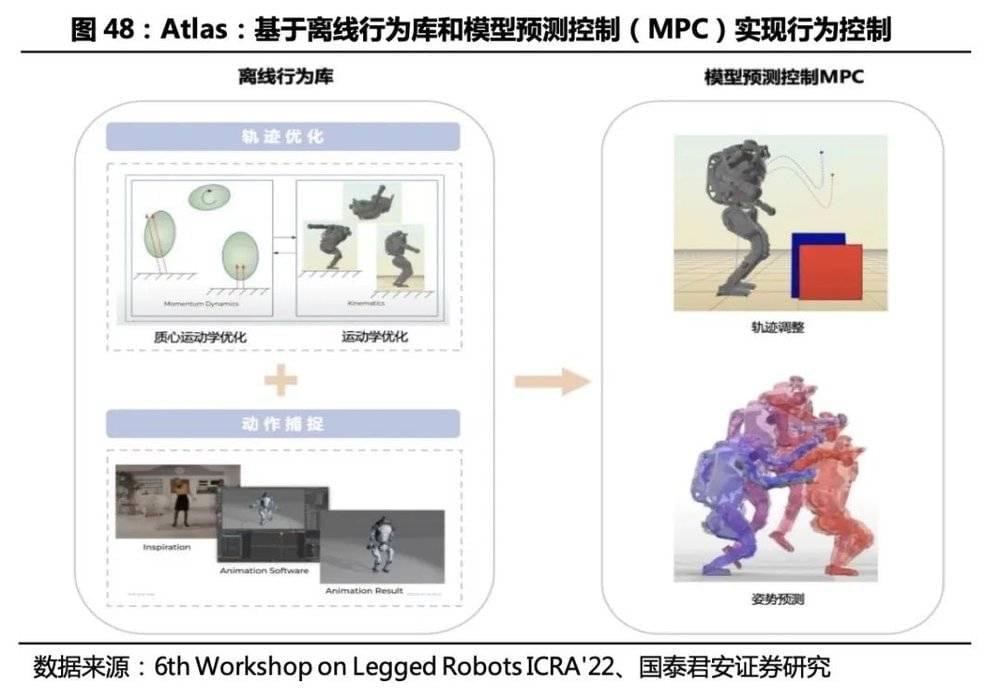
3.3.1.运动控制算法:思路相似,均为离线行为库和实时调整 波斯顿动力Atlas: 基于离线行为库和模型预测控制(MPC)实现行为控制离线行为库基于轨迹优化算法(质心运动学优化+运动学优化)和动作捕捉(MotionCapture)创建,技术人员可通过向库中添加新轨迹为机器人添加新功能;机器人被指定行为目标后,从行为库中选择尽可能接近目标的行为,获得理论上可行的动态连续动作。模型预测控制(MPC)根据传感器反馈的实时信息,基于行为库调整部分参数(力、姿势、关节动作时间等)的细节,以适应真实环境同理想的差异和其他实时因素。MPC这种在线控制方式允许机器人偏离模版行动,同时可以为两个行为(如跳跃和后空翻)间预测过渡动作,简化了行为库的创建过程。
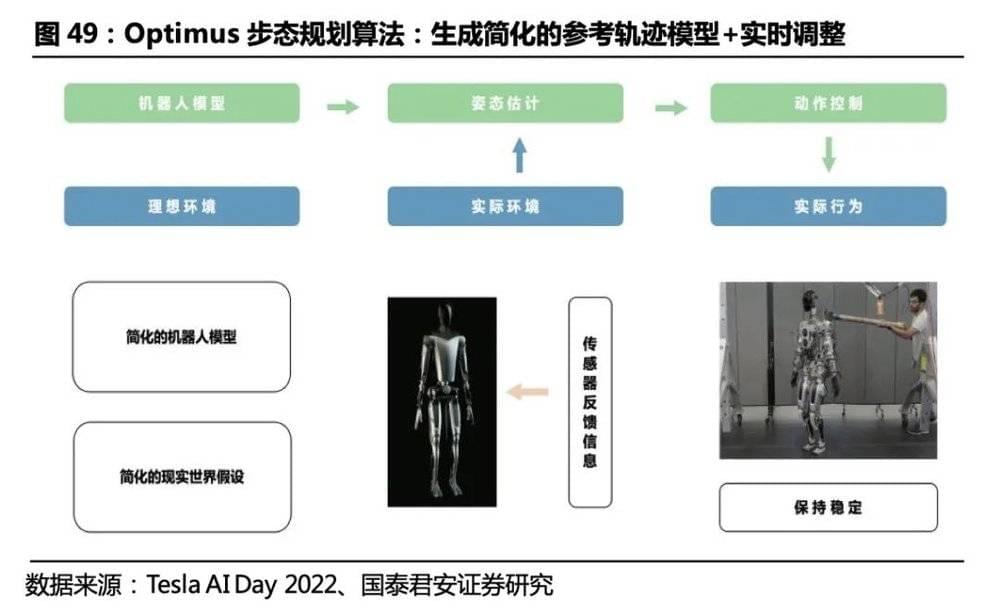
特斯拉Optimus: 步态规划算法思路和Altas类似,运动规划器生成参考轨迹,控制器根据传感器信息实时调整优化行为,控制算法尚不成熟步态控制算法中,运动规划器首先基于预期路径,生成参考轨迹,确定机器人模型的动力学参数。控制器基于传感器数据对机器人进行姿态估计,根据现实环境和理想模型的差异,对机器人行为参数进行校正,得到真实行为。此外,在连续的步态间,算法结合了人类行走时的脚步状态(脚掌初始着地->脚趾最后离地),结合上半身的协调摆臂运动,实现自然摆臂、大跨步以及尽可能直膝行走,提高行走效率与姿态。目前机器人的步态控制方案还不够成熟,抗干扰能力较弱,动态稳定性差,特斯拉技术人员表示Optimus的平衡问题可能需要18~36个月解决。
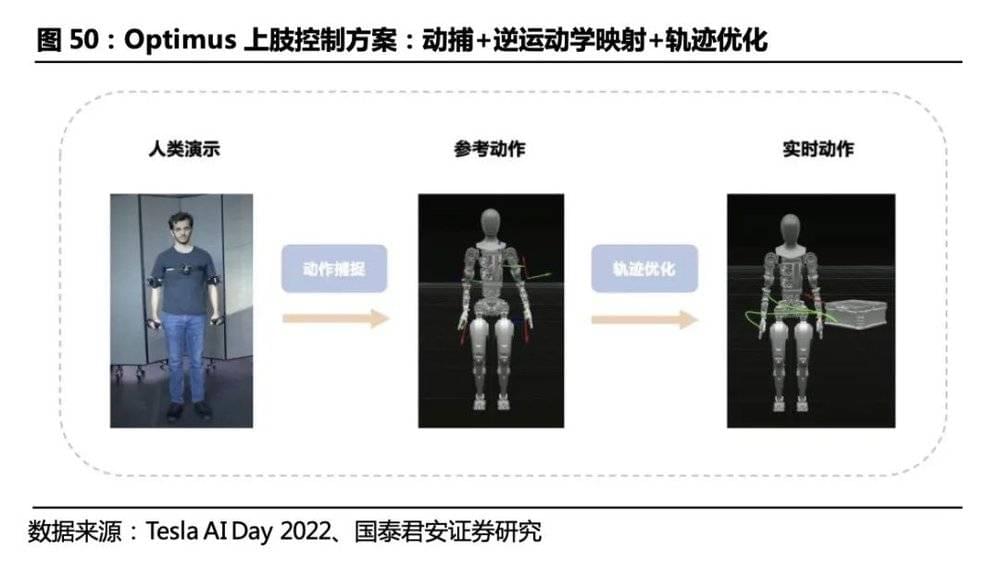
类似的,Optimus上肢操作借助基于动捕和逆运动学映射构成的离线行为库,通过实时轨迹优化实现自适应操作。
3.3.2.运动控制器:多为自主设计,不同厂商需求差异大人形机器人采集并处理多种模态数据,执行机构复杂程度远高于工业机器人,对控制器实时算力、集成度要求高。人形机器人传感器类型、数量远超工业机器人,行动过程中需同时完成3D地图构建、路径规划、多传感器数据采集、采集运算并实现闭环控制等等,流程相对繁杂,数据维度、数据量均高于工业机器人,对算力要求高。工业机器人一般通过外接的图像采集卡和图像处理软件实现识别和检测;移动场景下的人形机器人要求图像处理器集成于控制器芯片中,对芯片集成度有要求。
人形机器人控制器多为自主设计,不同厂商需求差异大。目前人形机器人下游场景的不确定性较强,不同厂商研发的机器人驱动方案(如驱动方式、电机方案)、感知方案(纯视觉、多传感器融合等)、控制算法差异较大,机器人对控制器的算力、存储等有不同的需求,因此控制器的组成有差异,以自主设计为主。我们认为人形机器人控制器采用分布式控制系统的方案可能性较大,即由一个核心控制器和多个小型控制器构成,其中小型控制器用于驱动各个身体区域的关节。
波士顿动力Atlas: 机器人本体搭载3台工控机负责运控系统的计算控制器接收来自激光雷达、ToF深度相机的数据,生成地图和路径后基于离线行为库中规划目标行为;实际运动过程中通过采集 IMU、关节位置、力、油压、温度等传感器数据,针对动作序列进行实时调整和优化。
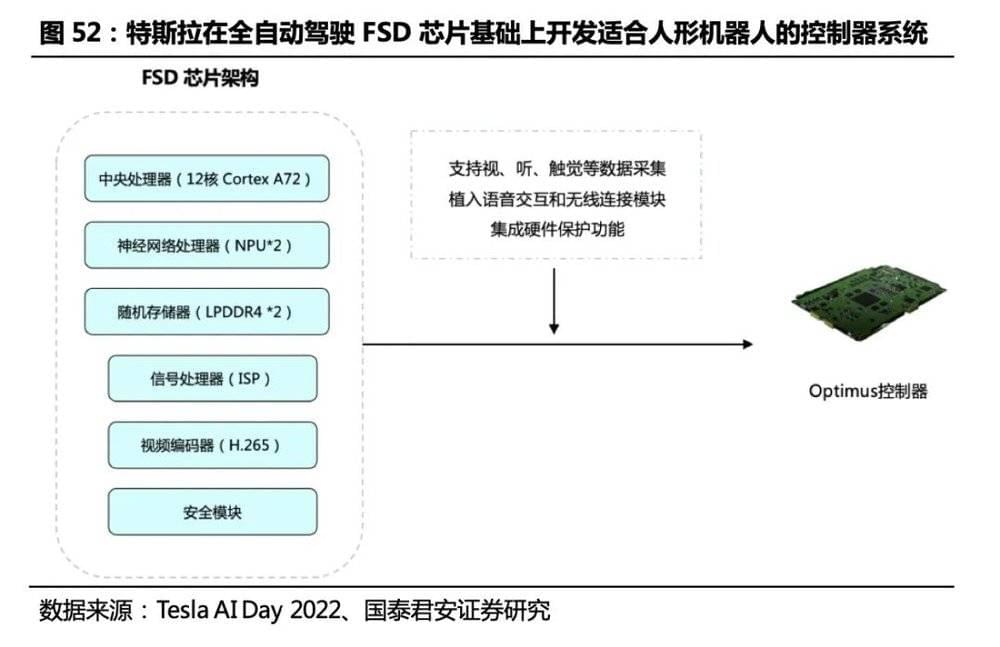
特斯拉Optimus: 复用特斯拉汽车的感知和计算能力,在全自动驾驶FSD芯片基础上开发适合人形机器人的控制器系统FSD芯片集成了中央处理器、神经网络处理器(NPU)、图像处理器(GPU)、同步动态随机存储器(SDRAM)、信号处理器(ISP)、视频编码器(H.265)和安全模块,能高效率地实现图像处理、环境感知、通用计算和实时行为控制。为了匹配人形机器人和汽车的需求差异,Optimus控制器芯片在FSD芯片基础上做了适应性修改,增加了对视、听、触觉等数据采集实现多模态信息输入支持,植入语音交互和无线连接模块支持人机沟通,具备硬件保护功能以保障机器人和周边人员安全,进而实现行为决策和运动控制。
四、投资结论及产业链梳理
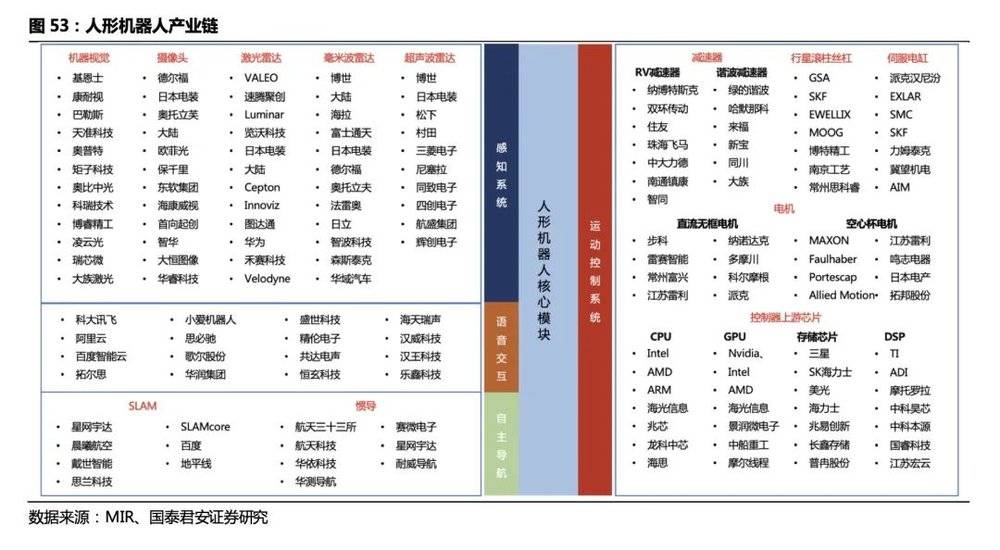
目前人形机器人厂商多为自行采购上游零件,集成以实现对自家机器人的适配,控制算法和控制器的设计是机器人运动控制的核心和壁垒,可能会延续工业机器人厂商负责本体制造+控制器部分的产业链分工。目前,通用的人形机器人控制器方案还没出现,出现类似工业机器人运动控制卡这样通用的、集成化解决方案作为独立的产品供应至少需要人形机器人量产之后。
相比工业机器人,人形机器人硬件需求更复杂、更多元。减速器、伺服电机、线性执行器、滚柱丝杠是人形机器人的运动控制产业链中价值量较大的硬件设备。
1)电机:数量更多、品类更丰富,需满足全身各关节的驱动需求,手部需采用微型电机。
2)减速器、传动装置:数量更多,旋转执行器延续了对RV、谐波减速器的需求,线性执行器中需要用到行星滚柱丝杠作为线性传动装置。
3)环境感知:区别工业机器人在固定场景外接机器视觉设备实现识别的方案,人形机器人场景复杂,需采用激光雷达、摄像头等方案实现环境感知、三维重建并实现路径规划,对设备品类、算法、实时算力要求更高。
4)运动控制:类似于工业机器人,运控算法均是厂商自研,开发难度大,是核心竞争力之一;人形机器人传感器数量、品类、执行机构复杂程度远高于工业机器人,对控制器实时算力、集成度要求高。